"There are three things important in the database world: Performance, Performance, and Performance." Bruce Lindsay
Let me start with a real world effect of right modeling on the application performance. Here's the except from a talk by Amadeus engineers on their customer experience management application (traveler loyalty app) which they migrated from an enterprise RDBMS to Couchbase.
Performance comparison between the enterprise RDBMS and Couchbase:
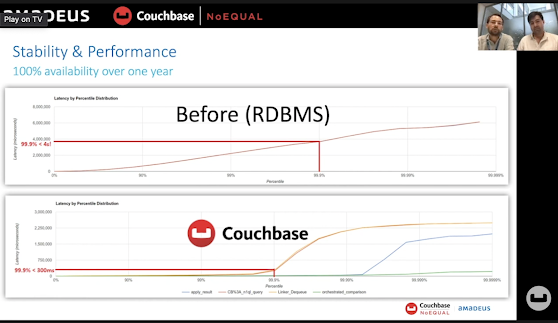
"In terms of stability and performance, it was quite amazing as well. It has 100% availability for over one year and counting. In terms of performance, it was night and day compared to what we had before, basically these graphs give you response time percentile. First graph is our previous implementation using standard RDBMS. With RDBMS, in 99 percentile of the cases, we were responding in less than 4 seconds from the database. Now in Couchbase, for 99.9 percentile of the cases, we're responding in less than 300ms. That's more than 10 times faster [13.3 times]. That's quite amazing. In fact, average response time in Couchbase corresponds to 90th percentile in RDBMS... which is amazing. To be honest, when developers extracted those data initially they thought it was a problem of measurement. It's really night and day. The performance in Couchbase is really much more stable. As you can see, the graph for 99th percentile is flat, which is amazing." - Amadeus
See the full presentation here:
I've worked on RDBMS R&D for a long time. It's hard to beat RDBMS performance by that margin. Really hard. How did Amadeus achieve this using Couchbase?
Answer:
- Superior Data modeling using JSON
- Access methods and optimizations in N1QL (SQL for JSON)
DATA MODELING FOR JSON
Couchbase has a good number of resources with detailed advice on how to migrate from relational model to Couchbase JSON model. Best practices, tips, and things to avoid. These are the prime resources.
- JSON Data Modeling Guide
- A JSON Data Modeling Guide
- JSON Data Modeling for RDBMS Users
- Moving from SQL Server to Couchbase Part 1: Data Modeling
Couchbase 7.0 has the Bucket->Scope->Collection three level data organization. Detailed explanations for this are here and here. So, with Couchbase 7.0 and above, below are the database objects you use for your physical data modeling. Using scopes and collections, you can avoid having to use the type in each document, index definition and queries. All these become a bit more natural. While you can map a table to a collection and simply move a relational table to a Couchbase collection, to reap the full benefit of the model, you need to remodel to exploit the nested structures of JSON: objects and arrays. Just like Amadeus did.

NOTES ON ACCESS METHODS AND PERFORMANCE IN COUCHBASE
The main purpose of going through logical and physical data modeling exercise to improve programmability and performance. Easier the developer can write programs to access the required data the better it is. This program has to perform to meet the SLAs. That depends not only on the logical & physical data model, but also the access methods and the optimizer in the system. Here are the data access APIs & languages available via Couchbase SDKs
- Direct JSON document access & manipulation (e.g. Java SDK)
- Direct sub-document access & manipulation. (e.g. Java SDK)
- N1QL - SQL for JSON for OLTP access
- This is a rich language supporting various select, join, project operations
- Numerous indexes on scalars and arrays for range and pattern scans that covers all the use cases that Oracle does. Couchbase has a built-in index advisor as well as a service.
- state of the art optimizer
- ACID transactions
- N1QL - SQL for JSON for Analytics
- Rich enhanced SQL language for easier analytics. Here's a tutorial
- massively parallel distributed execution for analyzing large sets
- Full Text Search
- Language aware, language based search
- sophisticated query language to mix search with range scans
- Fully integrated with N1QL and tooling.
- Eventing
- Helps you to easily code down-stream actions after changes to the data.

EXAMPLE QUERY FROM AMADEUS
Now, let's look a bit closer to how Amadeus achieved 13 times improvement over an enterprise RDBMS.
Here's their typical query to fetch qualified Couchbase query:

Text version below.
SELECT DATA,
META(DATA).id,
META(data.cas)
FROM
(SELECT RAW id
FROM
(SELECT id,
SUM(weights)
FROM (
(SELECT META().id AS weights
FROM prdcem_xx
WHERE TYPE = "links"
AND OWNER = "XX"
AND (ANY param IN `identity`.`Contact`.`Emails` SATISFIES (param = $1) END)
LIMIT 50)
UNION ALL
(SELECT META().id,
1 AS weight
FROM prdcem_xx
WHERE TYPE = "links"
AND OWNER = "XX"
AND (ANY param IN `identity`.`Contact`.`Phones` SATISFIES ((REVERSE(param.`Number`) LIKE $2) OR (reverse(param.`Number`) LIKE $3)) END)
LIMIT 50) UNION ALL
(SELECT (META().id,
` AS weight FROM prdcem_xx WHERE type = "links" AND owner = "XX" AND (ANY param IN `IDENTITY`.`Name`.`NAMES` satisfies [param.`FirstName`, param.`Lastname`] = [$4, $5] END)
LIMIT 50)) AS union_query
GROUP BY id
ORDER BY weights DESC) AS order_query) AS dkeys
INNER JOIN prdcem_xx AS data ON dkeys- Pipelining: The FROM clause can process data from collections or other SELECT statements -- both are data sources returning a set of JSON documents. Pipelining (subqueries) can be nested to any level and in any place a table expression is allowed.
- Array handling: The predicate (ANY value in arrayfield SATISFIES value = "abc" end) looks for the value abc in an array array field. Array is the key difference between relational and JSON model. You can arrays of scalars Any database can store arrays, but not everyone can efficiently index and search within arrays. Couchbase supports efficient indexing of index keys using GSI and FTS. The search index supports indexing and scanning multiple fields of multiple arrays in an efficient way.
- Indexing: Indexing allows simple keys, arrays, array expressions, scalar expressions and more. This enables developers to execute expressions (reverse(param.`Number`) LIKE $3) efficiently by using them as an index key.
- Optimization: The eventual query plan created should be efficient at each stage of the pipeline as well as the whole query. For example, the optimizer should select the right index for each sub query, but also push the LIMIT 50 to the index scans. This avoids the need to transfer and process unnecessary data.
- SET operations: N1QL operates on set of documents. Apart from select, join project, real applications need additional set operations: UNION, UNION ALL, EXCEPT, EXCEPT ALL, INTERSECT, INTERSECT ALL. N1QL supports all these standard operations.
- Index Partitioning: Couchbase collections are automatically hash partitioned on the document key. The GSI indexes can be non-partitioned (on a single node, that's default) or hash partitioned on any expression. Search indexes can also be partitioned (hash, on the document key) to more than one partition.
Couchbase is a modern database that's greater than sum of its parts. Each feature is integrated with others to make the developers life easier. Hope you benefit from it as much as Amadeus did!
Thank you for your articles that you have shared with us. Hopefully you can give the article a good benefit to us. AI-900: Azure AI Fundamentals
ReplyDelete