
Insights come from observing and analyzing data from all sources. Couchbase Columnar helps quickly analyze data from a variety of data sources with zero-ETL.
The purpose of computing is insight, not numbers.
- Richard Hamming
Capella Columnar is an advanced real-time analytics database service from Couchbase, targeted for real-time data processing, offering SQL++ for processing JSON (semi-structured) data and more. This service enables data to be managed locally and streamed continuously from both relational and NoSQL databases, or simply process data on S3. The columns or fields of the source are directly mapped to a field in the JSON document at the destination automatically. This is really a zero-ETL operation. A key feature of this system is its ability to continuously stream data, making it immediately available for querying, thus ensuring near real-time data processing.
At the heart of Columnar's architecture is a Massively Parallel Processing (MPP) engine, specifically designed to scale both capacity and performance. The SQL++ query processing system has been meticulously developed to leverage the scalable cloud architecture, incorporating efficient methodologies like distributed hash joins, a custom cost-based optimizer, and smart scanning of data on S3. The storage mechanism of Columnar is strategically engineered to boost performance while minimizing costs. It utilizes the first-in-the-NoSQL industry columnar storage for semi-structured data to reduce the storage footprint and improve query performance. Additionally, the system cleverly separates storage and compute, using S3 for persistence while caching data partitions on individual nodes for quick access. Designed for ease of use, the entire service can be deployed swiftly with just a few clicks.
Users can interact with their data through a built-in workbench, or engage in natural language querying with the built-in GenAI tool iQ. The service allows for versatile output formats including JSON, tabular forms, or charts. Complementing its robust architecture, Columnar offers SDKs in all popular programming languages and native support for BI tools like Tableau and PowerBI, making it a comprehensive solution for modern data analytics needs. Enough details.
Now, simply bring your data and accelerate your insights.
Motivation For the Columnar Service
As the holiday season approaches, a major global retailer faces a dire predicament that extends far beyond its corporate walls, directly impacting its end customers. Consider the frustration of shoppers who encounter out-of-stock notifications for their desired items, or who are bombarded with irrelevant promotions, all because the retailer is unable to quickly interpret and act upon the data pouring in from various sources. This is not simply a back-end data problem; it is a front-line customer experience crisis. Lost sales, diminished customer loyalty, and missed market opportunities are just the beginning. The retailer's inability to swiftly analyze and utilize data from its various databases and formats is costing not only in terms of revenue but also in terms of customer satisfaction and brand reputation. The holiday season, which should be a time of peak performance and customer engagement, is at risk of becoming a period of missed connections and lost potential.
In the dynamic landscape of enterprise technology, where a mosaic of databases drives crucial operations from customer transactions to content management, a pressing challenge has surfaced. Enterprises navigate a complex web of systems: Oracle managing ERP, Couchbase powering e-commerce functionalities, MongoDB steering content management, with critical customer data often tucked away in S3 files. This diverse data environment, although instrumental in fostering microservice autonomy and scalability, uncovers a daunting challenge: the real-time identification and resolution of bottlenecks in the customer journey. This issue is emblematic of a broader spectrum of hurdles that modern enterprises encounter in their quest to orchestrate an effective "observe, orient, decide, and act" (OODA) loop, a cornerstone for operational efficiency and competitiveness today.
Gaining actionable insights requires harnessing a vast expanse of data. The key lies not just in amassing this data but in rapidly analyzing and effectively visualizing it in its myriad forms to unearth those critical insights. This is precisely the objective at the heart of Couchbase's Capella Columnar service. Designed to bridge the gap between extensive data collection and insightful analysis.
Details of Couchbase Columnar Service
Since a picture is worth a thousand words, the picture below should answer all your questions! :-) For those who are even more curious, read on...
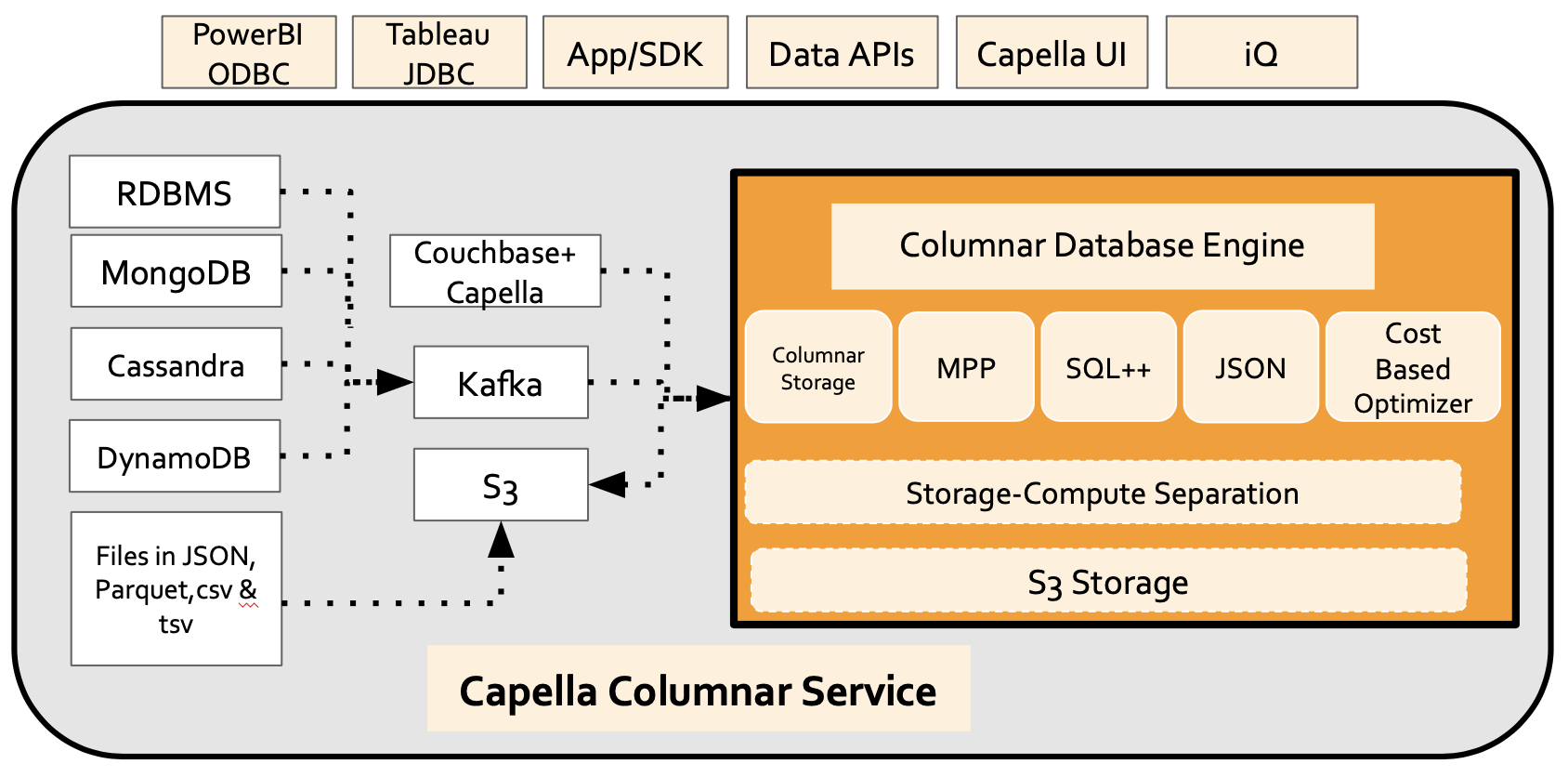
It's a sophisticated service with significant features to make it easy to analyze. It's difficult to provide all of the details in a single article. Here's an overview!
Data Objects
Columnar service allows you to create databases that can have scopes. A scope is a logical entity that can have one or more collections and their indexes. Each collection can be simply a "standalone collection" whose data is manipulated by SQL++ DML statements: INSERT, UPSERT, DELETE, SELECT.
The collection can also point to a collection or a table in an external database instance. These external databases can be Couchbase, MongoDB, DynamoDB, Cassandra, or even RDBMS such as MySQL. With a few clicks to provide secure access to data, you can set up a collection that has a copy of the remote data. Not only does it copy the data but it then automatically sets up the infrastructures to continuously stream changes at a remote database to your collection in a matter of milliseconds to seconds. The data is immediately available for analysis.
The next type of collection is the "external data set" that simply points to a file or a structure on S3. The data can be in JSON, Parquet, CSV, and TSV now with more formats to be supported in the future. The support for S3 is designed to handle very large data processing by identifying and reading only the data required by the query.
Data Sources
Currently, we support the following non-local data sources:
- Couchbase on-prem
- Couchbase Capella
- S3 data in CSV, TSV, JSON, and Parquet. More format support is on the way.
- MySQL
- MongoDB and MongoDB Atlas
- DynamoDB
- Cassandra support is on the way
Architecture
The core database, built on a Massively Parallel Processing (MPP) engine, uses JSON as its super data model to support the flexibility required by modern data. This system supports SQL++ query language that supports the standard select, join, and project operations as well as advanced nesting, unnesting, windowing, rollup, and cubing operations declaratively. It's equipped with indexes on both scalar and array data types. Queries on these are efficiently planned by a specialized cost-based optimizer, tailored for JSON and MPP architecture. SQL++, enhanced from SQL, is adept at handling both flat data and JSON and its data types. This capability positions SQL++ as an effective query language for managing heterogeneous data, mirroring the role of JSON as the foundational data model.
For a more comprehensive understanding of this technology and the various facets of the core database server, accompanying papers offer in-depth analyses and insights. Here are papers that give you a deeper look into technology and many aspects of the core database server.
- Architecture Overview: Couchbase Analytics: NoETL for Scalable NoSQL Data Analysis
- Array Indexes: On Multi-Valued Indexing in AsterixDB
- SQL++ For SQL Users: A Tutorial
- Theory behind SQL++: The SQL++ Query Language: Configurable, Unifying, and Semi-structured
Storage
We now focus on storage within Capella Columnar, specifically its columnar storage model. The combination of the JSON document model with columnar storage is highly advantageous from a user perspective, though it presents significant implementation challenges due to the flexible schema inherent in JSON. Typically, a JSON document stores considerably more data than a standard row in a traditional RDBMS. This difference becomes particularly relevant during data analysis, which often involves just a few columns per query, leading to substantial I/O savings. When implemented effectively, columnar storage not only offers these I/O benefits but also brings additional advantages in terms of data compression. So, the columnar storage improves analysis performance and reduces TCO simultaneously.
The columnar storage utilized in Capella Columnar is the culmination of research conducted at the University of California at Irvine and subsequently refined and hardened by Couchbase. Again, detailed information on columnar storage is in the paper "Columnar Formats for Schemaless LSM-based Document Stores."
iQ for Columnar
iQ is a natural language interface to interact with your data by generating the SQL++ query for your ask. For Columnar, we've improved the query generation quality for joins. And finally, with one single click, you can go from your natural language question to a chart. Click here to play the GIF.

Comments
Post a Comment