[Repost of my article: https://dzone.com/articles/split-and-conquer-efficient-string-search-with-n1q ]
Consider my DZone article: Concurrency Behavior: MongoDB vs. Couchbase. It’s a 10+ page article. For any application, indexing and supporting searching within the full text is a big task. The best practice for search is to have tags or labels for each article and then search on those tags. For this article, tags are: CONCURRENCY, MONGODB, COUCHBASE, INDEX, READ, WRITE, PERFORMANCE, SNAPSHOT, and CONSISTENCY.
Let’s put this into a JSON document.
It's one one thing to store the tags. It's another thing to search for a tag within the string. How do you search for the COUCHBASE tag within the tags? How do you search for a specific string within this “tags”?
In SQL, you can do the following:
Create an index on tags, you get the following plan:
You need to use the pattern “%COUCHBASE%” because the string pattern could be anywhere within the tags string. Whether you do a primary scan (table scan) or an index scan, this query is going to be slow on a large data set, as it has to scan the entire data set or the index to correctly evaluate the predicate.
Two observations here:
- While the predicate "%COUCHBASE%" looks for the word COUCHBASE anywhere in the string, it's usually in there as a separate word, tag or label.
- Applications and users typically search for the whole word.
Now, let's see how N1QL makes this fast, easy, and efficient.
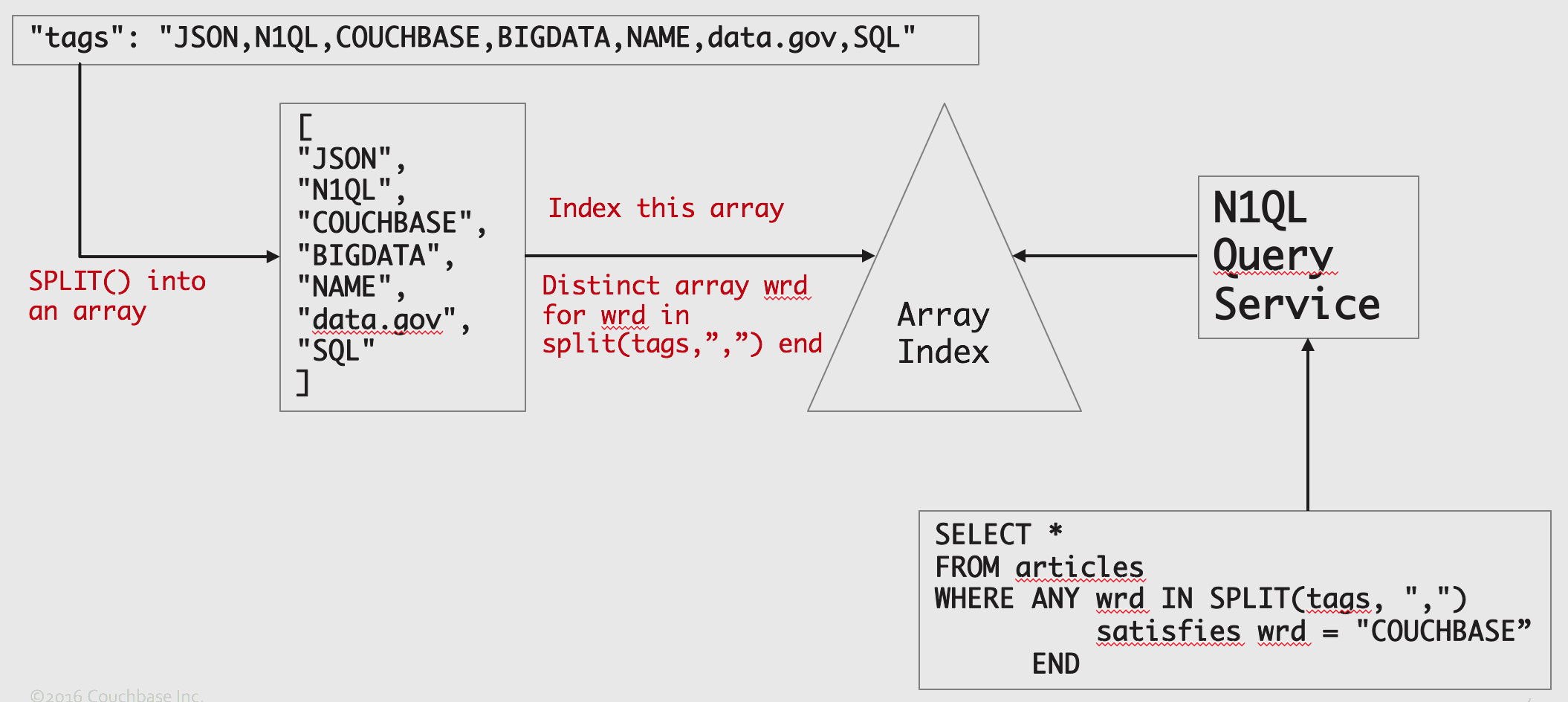
Let’s first look at the SPLIT() function. SPLIT() can take any string and a separator, and return array strings.
Once you have an array, you can query the data based on array predicates.
Note: System:dual always has a single document with null in it.
Let’s try to find something that doesn’t exist. Since the predicate is evaluated to be False, nothing is returned.
We can convert the tags string into an array of strings and then lookup the value in the array instead of searching within the whole string.
Now, we’ve converted the problem from string search to array look up. Couchbase 4.5 has a flexible array indexing capability to index arrays. Exploiting this, we can look up the value in the array index very efficiently.
Here's the approach:
Let’s try this end-to-end example on Couchbase 4.5 or above.
1. Create a bucket called articles.
2. CREATE primary index
3. INSERT the following documents.
4. CREATE the ARRAY INDEX
5. Let’s query the data now.
This explain shows the array index is used and the spans created for the index scan.
Let’s get greedy. Now that we have an efficient way to look up the tags, let’s make it case insensitive.
1. Create the array index, but convert the data into lower case before you index it.
2. Start querying.
You can even put a LOWER expression on the tag you’re looking for to make the query generalized.
More Use Cases
Tags aren’t the ONLY type of data stored in regular string pattern. Tags are NOT the only ones to benefit from the technique. Here are some other examples:
- Airline route information
- Variable list of employee skills
- CSV processing: Handling data import from CSV.
- Hashtags search
Conclusion
N1QL is designed to handle the flexible schema and structure of JSON. Array indexing helps you to process and exploit arrays in useful ways.
References
- N1QL: http://query.couchbase.com.
- Additional string search techniques in Couchbase:
- Couchbase: http://www.couchbase.com.
- Couchbase Documentation: http://docs.couchbase.com.
Comments
Post a Comment