
We chose to run YCSB and do the other performance work in Couchbase 4.5. Not because it's easy, but because it's hard; because that goal served us to organize and measure our effort and features and hold them to a high standard.
Like all the good benchmarks, YCSB is simple to support and run. Most NoSQL can run YCSB benchmarks. The difficulty is in getting those numbers high. Just like the TPC wars in 90s, the NoSQL market is going through its YCSB wars to prove the performance and scalability.
Cihan Biyikoglu has discussed the combination of technologies within Couchbase helping customers scale and perform. In this article, we'll focus on Workload-E in YCSB — How Couchbase is architected and enhanced in Couchbase 4.5 to win this round of YCSB against MongoDB.
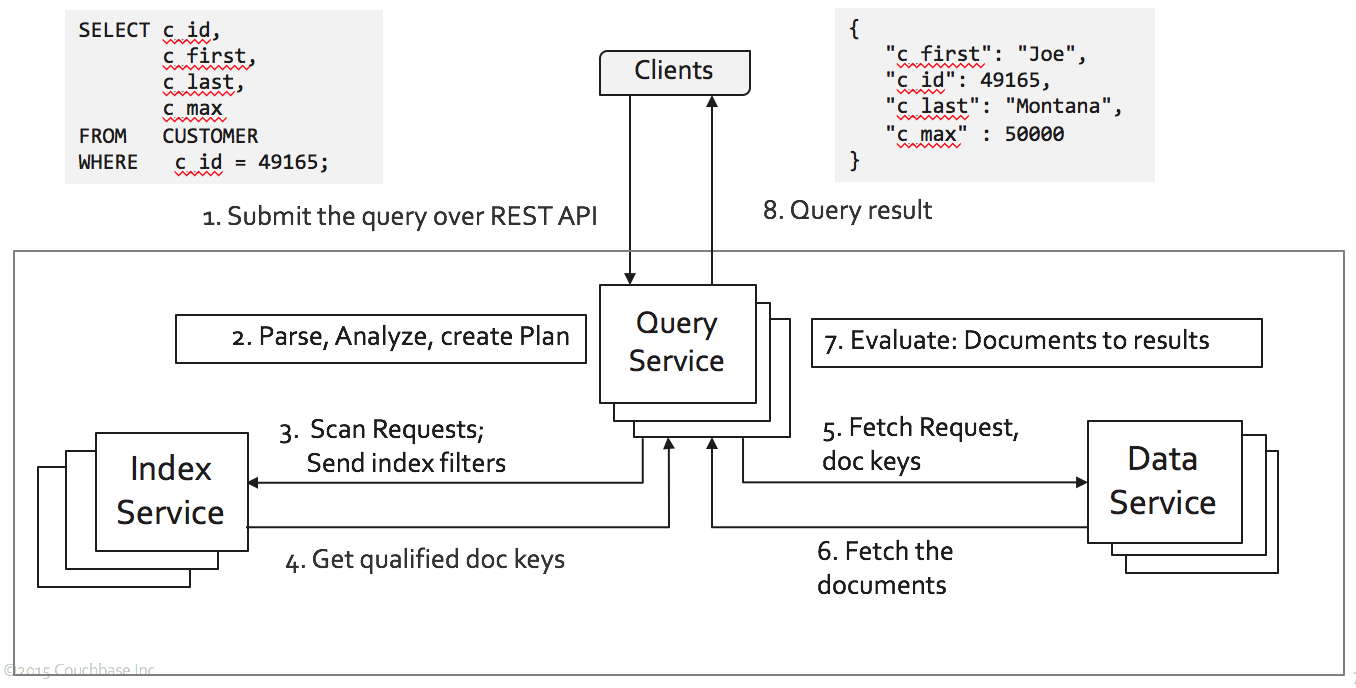 Figure 1 Couchbase Architecture.
Figure 1 Couchbase Architecture.
To put it simply, Couchbase is a distributed database. Each of the critical services — Data, Query, Index — can be scaled up and scaled out. How you scale is your choice.
We used workload-A and workload-E to measure the performance. In this article, we'll focus on workload-E. The workload-E simulates queries for threaded conversations, where each scan is for the posts in a given thread (assumed to be clustered by thread ID). In all, 95% of the operations are scans and 5% of the operations are inserts to the database.
The short scan operations can be written in SQL with the following query:
In Couchbase, the YCSB data is represented as the following:
The Couchbase port for YCSB is available at:https://github.com/brianfrankcooper/YCSB/tree/master/couchbase2
Below is the actual query in Couchbase. The meta().id expression in the query refers to the document key of the document. In Couchbase, each document in a bucket will have a unique key, referred to as document key.
Once you load the data, you simply create the following index. You're ready to run the YCSB workload E.
When we ran this on Couchbase 4.0, we knew we had our work cut out. In this article, we'll walk through the optimizations done in 4.5 to improve this query. What we've done for this query applies to your index design, resource usage, and performance of your application queries.
In 4.5, when you execute this query, here is the plan used:
Each query goes thru multiple layers of execution within the query engine. The query engine orchestrates query execution among multiple indexes and data services, channeling the data through multiple operators.
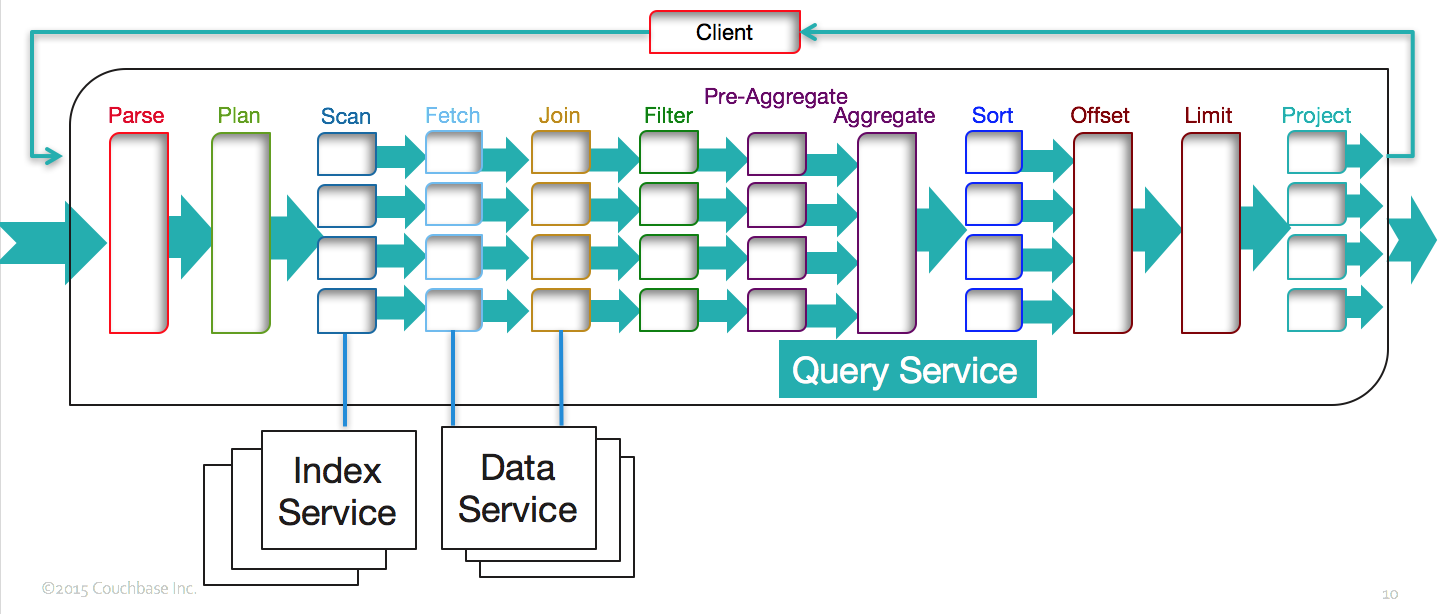
Let's take this and explain the performance optimizations, indexing features implemented, exploited to get the best performance
1. Index Scan
Here's the explain snippet on index scan. In this case, we use the index meta_i1, with a predicate specified by the spans and the index scan is expected to return the first 50 qualified keys. Let's examine each of those decisions in in subsequent sections.
2. Index Selection
Index selection in Couchbase is based on the predicates (filters) in the WHERE clause of the statement only. The index selection is made solely based on predicates and not any references to any other clauses like projection, grouping, ordering, etc.
In this statement, the WHERE clause is: meta().id >= "xyz1028". In this case, the match is quite straightforward. The index meta_i1 is chosen.
This is the very basic case. There are many subtle things about creating the right index and improving the throughput of the index scans. Let's discuss one by one.
In Couchbase, you can create many types of indices. We now have a secondary index meta_i1 on the document key (meta().id). In couchbase, you can create multiple indexes with same set of keys, but with different name.
With these indices, the plan would choose the primary index, saving memory and CPU resources.
3. LIMIT Pushdown
In pagination queries, it's typical to limit the results what the screen can show. OFFSET and LIMIT keywords in the query help you to paginate through the resultset. From the application point of view, OFFSET and LIMIT is on the resultset of the whole query after all the select-join-sort-project operations are done.
However, if the index scan is being used for filtering the data, data is already ordered on the index keys. Then, if the ORDER BY is on the index keys, ascending and in the same order as the index keys, we can exploit the index ordering to provide the results in the expected order. This is significant, without the pushdown, we need to retrieve all of the qualified documents, sort them and then choose the specific window of results to return.
The primary index matches the predicate in the query. The ORDER BY is ascending by default. So, the predicate and the LIMIT is pushed down to the index scan. The plan includes the limit field with the number pushed down as well. When you want a high performing pagination queries, the LIMIT and OFFSET should be pushed down to the index scan.
Another thing to notice is that, because the LIMIT is pushed down to index scan, the order, offset, limit operators become unnecessary and are removed from the plan. The best optimizations simply avoid the work altogether. This is one of them.
If we didn't have this optimization in place, or when the ORDER BY does not follow the index key order, you'd see something like this in the query plan.
If the query has both OFFSET and LIMIT, the sum of both are pushed down and the query engine simply skips over the keys required by the OFFSET.
3. Index Scan Range
The index scan range specified the by the spans. For this query, the range is (meta().id >= "xyz1028") and is specified by the following.
4. Type of the Index
In my cluster, I have the default standard global secondary index. In the plan, we can see this in the field {"using": "gsi"}.
Couchbase 4.5 introduces memory optimized index. A memory-optimized index uses a novel lock-free skiplist to maintain the index and keeps 100% of the index data in memory. A memory-optimized index has better latency for index scans and can also process the mutations of the data much faster. When you have memory optimized index, this will be{"using": "moi"}.
Summary
The duplicate indices, push down of the LIMIT, avoiding fetching extra keys from the index, avoiding sort — all done in a generalized way —helps optimize this YCSB scan query. This will help general queries with your application queries as well.
Comments
Post a Comment